
国家重点研发计划,高性能计算专项,对应指南3.1反应堆数值装置原型系统—数值反应堆(重大共性关键技术与应用示范类)。
由中国原子能科学研究院牵头,北京科技大学承担“数值堆应用软件开发”课题。
更安全高效的核反应堆对快速精准的堆芯理论计算、燃料和材料服役性能预测提出了迫切需求。基于先进耦合建模和大规模并行计算技术的数值反应堆已成为国内外领域前沿热点。数值反应堆(简称数值堆)不仅使上述需求成为可能,更为先进反应堆的设计优化、不同工况运行模拟优化、严重事故序列演示预测及燃料和材料研发提供一个经济高效的试验平台。
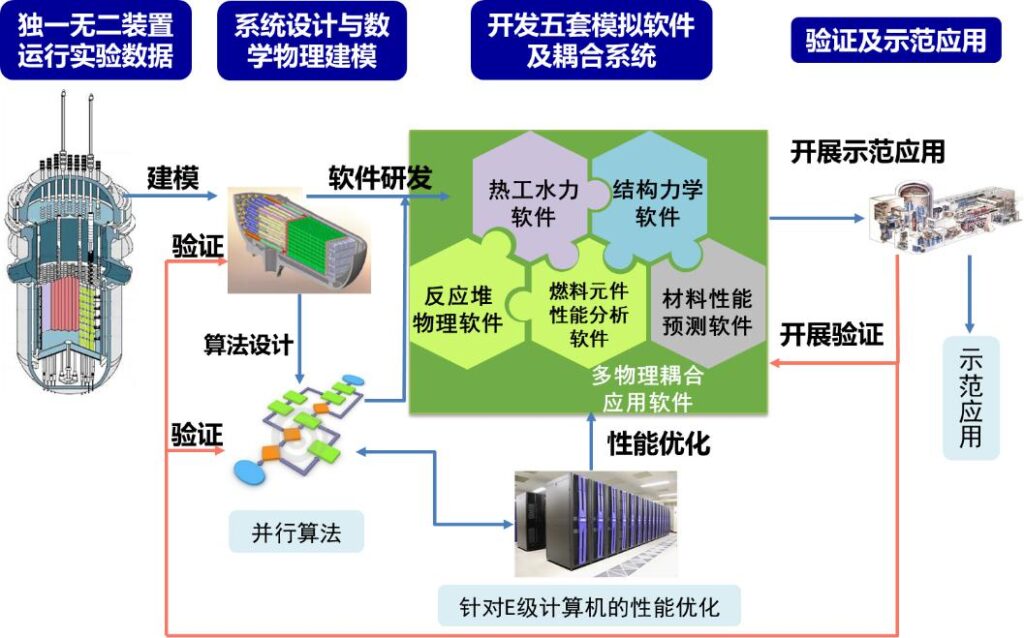
以E级超级计算机为依托,建立数值堆框架体系,明确各专业模块计算模型与算法及相互间的耦合规则和接口规范;研究面向E级计算的可扩展并行算法与优化技术;开发反应堆物理、热工水力、结构力学、燃料元件和材料五套高精细模拟软件,及它们之间多物理、多尺度、强非线性和流-热-固耦合应用软件系统;研究模拟验证及置信度分析的方法和技术,开展软件系统验证和数值堆原型系统典型示范应用。实现多物理、多尺度、强非线性和流-热-固耦合与验证,建立国内首个面向核能行业开放共享的数值堆原型系统,并实现四代快堆和二、三代压水堆示范应用。如图1所示。
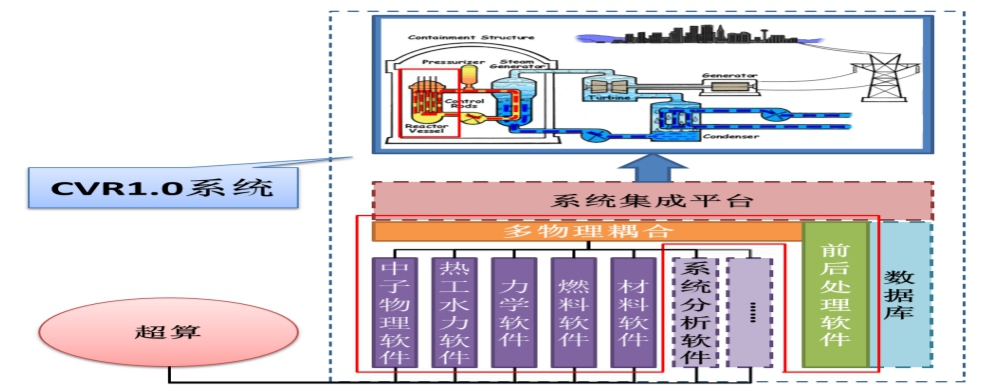
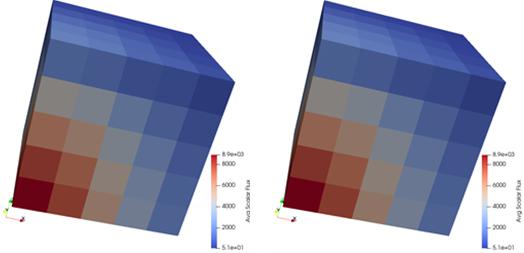
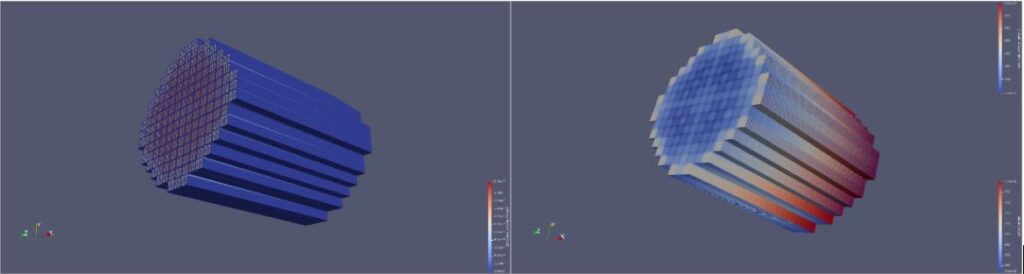
项目立项以来,秉承“瞄准应用痛点,发挥超算优势,聚焦核心技术,发展自主软件”的实施原则,完成了现役反应堆安全稳定运行以及先进堆型研发设计中对先进建模、高性能计算、多物理耦合等技术的需求以及现状分析,全面对标美国的三大数字反应堆项目(CASL、NEAMS、CESAR)的技术目标,依托典型国产超级计算机,研发了5类12套数值堆专用软件系统,建立了国内首个聚焦堆芯内部、局部单项稳态工况数值模拟的数值反应堆装置原型系统(CVR1.0系统)如图2所示,并初步实现四代快堆示范应用。该系统针对现役反应堆安全稳定运行以及先进堆型研发设计中对先进建模、高性能计算、多物理耦合等技术的需求,在明确数值堆装置形态和总体设计的基础上,突破了大规模、高保真模拟的全堆芯计算机建模与自动预处理,面向E级超算架构的数值堆软件并行优化,核结构材料辐照损伤大规模、多尺度模拟,数值堆流-热-固多物理场耦合模拟,高保真数值模拟程序的高效动态误差分析等关键核心技术,实现关键核心技术上的领跑、并跑。
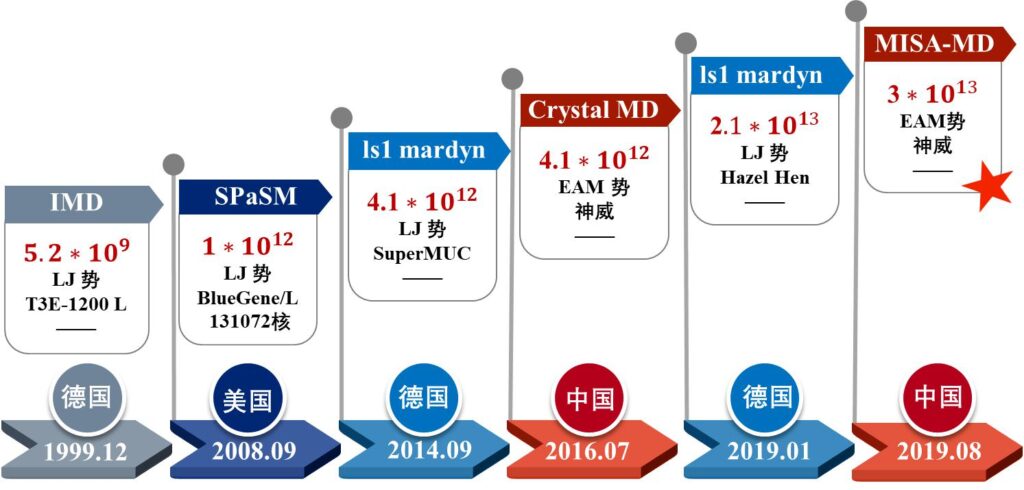
截止目前,共发表论文42篇,申请发明专利40余项,申请软著9项,形成规范3份。在数值反应堆关键核心技术、自主可控软件等方面,取得了一些亮点成果:
| 编号 | 软件名称 | CPU核数 | 模拟Box大小 | 内存占用(GB/CPU核) | 平均每原子内存占用(Bytes) |
| 1 | MISA-MD | 120 | 6003个晶格常数 | 0.64 | 191.2 |
| 2 | LAMMPS | 120 | 6003个晶格常数 | 1.77 | 527.2 |
| 3 | MISA-MD | 120 | 10943个晶格常数 | 2.66 | 130.9 |
| 4 | LAMMPS | 120 | 6683个晶格常数 | 2.66 | 574.9 |
| 核数(仅主核) | 模拟Box大小 | MISA-MD运行时间(秒) | LAMMPS运行时间(秒) | MISA-MD性能提升比例 |
| 64 | 256×256×256 | 267.78 | 319 | 16.06% |
| 128 | 256×256×256 | 137.51 | 175 | 21.42% |
| 256 | 256×256×256 | 69.48 | 103 | 32.54% |
| 512 | 256×256×256 | 35.01 | 59 | 40.66% |
| 1024 | 256×256×256 | 17.63 | 41 | 57% |
这些软件与目前市场上的相关专业软件相比,最大的特点是(1)他们是在数值核反应堆多物理耦合的统一模型约束下设计的,完全不同于解耦状态下的专业模拟软件。(2)软件完全紧密结合我国三台典型超级计算机进行并行优化,模拟规模、精度远远大于市场的专业软件。